> 爱游戏app官网入口-爱游戏app手机版官网 > 手机通讯 > 手机行情 > 正文
英伟达rtx 40系显卡解析:出色工艺带来出色性能,dlss 3是杀手锏|英伟达rtx40系显卡解析-爱游戏app官网入口
[摘要]英伟达在9月20日深夜举办主题演讲,正式推出rtx 40系显卡,包括卡皇rtx 4090以及rtx 4080 16gb以及rtx 4080 12gb,它们基于全新设计的ada lovelace gpu架构,除了全面提升的显卡规格之外,英伟达也为40系显卡带来了全新的dlss 3与光追计算单元,两个重要渲染引擎,让渲染性能更加出众。
英伟达在9月20日深夜举办主题演讲,正式推出rtx 40系显卡,包括卡皇rtx 4090以及rtx 4080 16gb以及rtx 4080 12gb,它们基于全新设计的ada lovelace gpu架构,除了全面提升的显卡规格之外,英伟达也为40系显卡带来了全新的dlss 3与光追计算单元,两个重要渲染引擎,让渲染性能更加出众。

但是紧接着而来的便是全面提升的价格,尤其是80显卡,相比较30系显卡价格提升十分地明显,那么40系显卡究竟为我们带来了怎样新的特性,这些功能值得消费者为其买单吗?
ada lovelace芯片:全新的工艺,暴增的性能
首先我们来说一下这颗由首位女性程序员ada lovelace命名的架构。作为卡皇,rtx 4090显卡的核心便是这颗ad102核心,整颗核心的面积为604.2平方毫米,相比较rtx 30系显卡还有所减小,但是晶体管数量却大幅提升,来到了763亿颗。
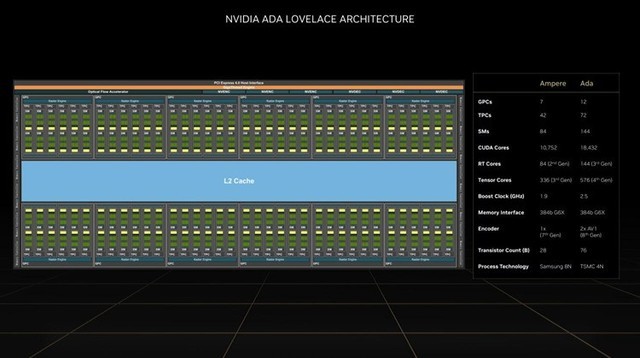
在总体的架构上,ada lovelace似乎与安培相差不大,一个计算单元内包括fp32计算单元,fp32与int32共享的计算单元以及第四代tensor core,同时也包括第三代的rt计算单元,让深度学习以及光追更加高效。
总体规模上,ada lovelace与安培相比就有突飞猛进的提升,例如图形处理集群从7个提升至12个,从而使得计算单元从84个飞跃至144个,也就是说一颗完整的ada核心,它能够提供最高18432颗流处理器,远超ga102的10752颗。此外光追单元也从84个提升至144个,深度学习单元更是从336个提升至576个,频率也从1.9ghz提升至2.5ghz。ada芯片能够有如此大的参数提升,最主要的原因便是制程的进步。在安培制程上,英伟达采用的是三星8nm制程,而到了ada时代,则采用定制版的台积电4nm制程,晶体管密度的提升极其明显,也让芯片面积在有所减小的情况下晶体管数量还能增长如此凶猛。
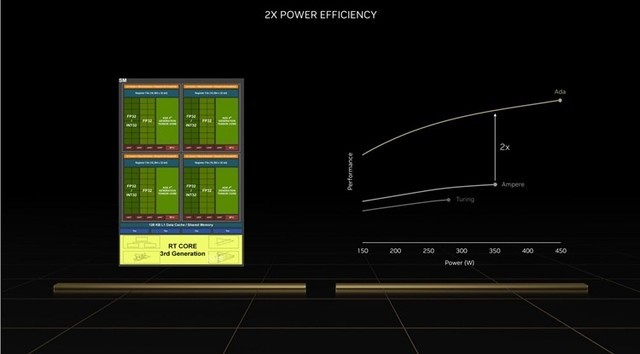
除此之外,英伟达还表示在ada gpu的能耗比是安培的2倍,着色器渲染能力达到了83tflops,同样是上代的两倍,并且光追算力猛增至191tflops,更是上代2.8倍。而与深度学习有关的fp8张量计算更是达到了恐怖的1.32pflops,已经是上代核心的5倍。在游戏方面,英伟达也称ada在光栅性能上是安培的2倍,而光追性能更是后者的四倍。
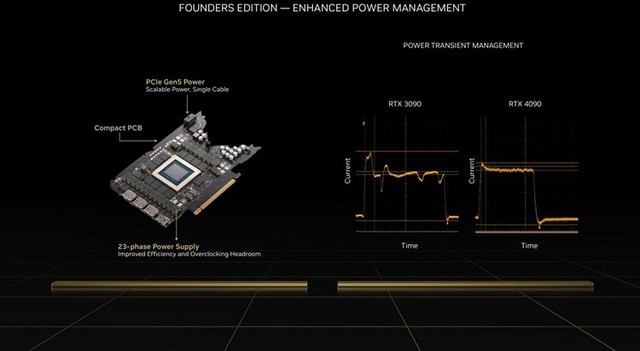
对于玩家来说,rtx 40系显卡也大幅改善了运行时候的功耗表现,运行更加平稳,不会出现大规模的瞬时功耗提升,这对于想要添置大功率的玩家来说尤其重要。毕竟高端电源,多1w的供电,可能需要花费1.2甚至1.5元的预算。也正因为有了如此强大的计算性能,可以让ada gpu实现更多的工作,例如dlss 3这一被老黄认为革命性的ai帧生成技术。
dlss 3:让ai生成帧,帧率大幅提升

dlss是英伟达的深度学习抗锯齿技术,借助英伟达的ai神经网络减少gpu的画面渲染,从而提升游戏的画面,自从图灵架构开始,dlss开始被消费者所认知。而这样提升画质的黑科技也经过了三代的更迭,初代dlss借助显卡本身的ai驱动以及神经网络进行画面的渲染,但是由于算力的限制,实际效果并不理想,尽管帧率有所提升,但是画面却异常模糊,特别是在一些动态画面中更是如此。
第二代也就是目前最主流的dlss 2.0时代,英伟达则选用了类似于dsr一样的技术,先让显卡以较低的分辨率进行渲染,随后再借助ai算力让画面变成高分辨率进行输出,当然相比较第一代dlss,第二代dlss无论是效果还是厂商接受度,都有着质的提升,并且消费者也越来越接受这项技术,此外友商也借助fsr以及xess实现与dlss类似的效果。而到了dlss 3的时代,已经不满足传统图形渲染的英伟达开始借助ai来自己创建渲染图像,通过插入到两个渲染图像之中,进一步降低gpu的渲染压力。
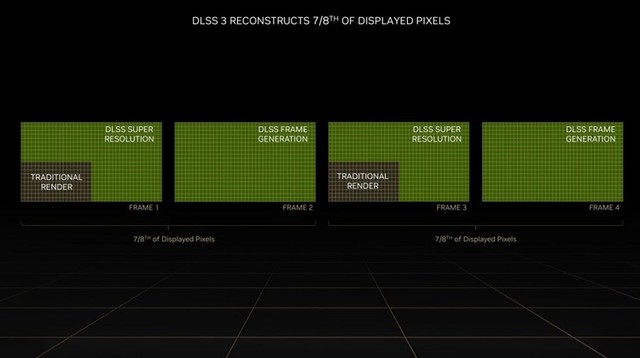
首先英伟达在ada gpu中加入一个叫光流加速器的硬件,而它也是实现dlss 3的核心。首先借助光流加速器,gpu分析画面之中运动物体的矢量数据,再根据卷积神经网络让ai自动渲染出游戏画面并插入到正常的游戏画面之中,这样便可以有效地提升游戏帧率,此外这种渲染方式也是游戏渲染领域的首次应用,前提自然是40系庞大的tensor core计算集群。
英伟达表示,dlss 3可以借助ai最高渲染出7/8的显示像素,在帧率上与不采用dlss的游戏相比,整整提升4倍。对于开启光追特效的游戏来说尤其有效。
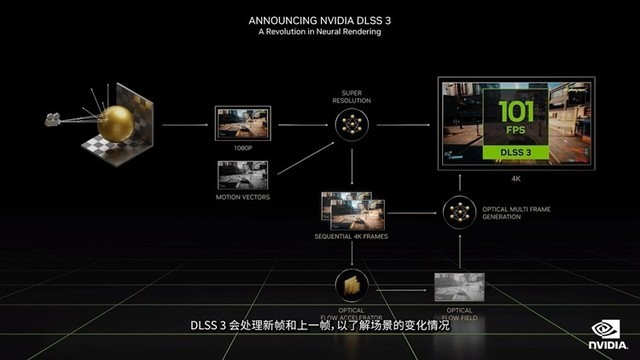
例如在发布会上公布的《赛博朋克2077》便从22帧左右飞跃至90余帧,甚至由于所有的图像帧均在gpu上进行,并不经过cpu,因此即使你没有一颗性能强劲的cpu,同样可以让游戏帧率有着显著的提升。
但是有人会担心,由于采用的是ai渲染帧,并且插入到两张正常的渲染帧之间,会不会造成画面延迟上升,对于3a大作的玩家来说,延迟或许不是什么问题,但是对于fps玩家来说,延迟却显得更加重要。对此英伟达表示游戏开发者以及游戏玩家可以借助nvidia reflex,有效地降低游戏的传输延迟,从而让即使开启dlss 3特效的玩家也能享受理想的延迟。

当然dlss 3并非所有的rtx显卡都可以享受,由于缺少光流加速器,rtx 20以及rtx 30系显卡直接和它说再见,此外英伟达也提供了一张关于dlss的特效表格,其中ai渲染与插帧技术为rtx 40系显卡独享,而rtx 40/30/20系显卡都支持原来的画面缩放功能,至于nvidia reflex,从gtx 900系显卡就可以支持这项特效。目前已经有超过35款游戏支持dlss 3,将于10月份陆续和大家见面。
全新渲染引擎:图形渲染更高效
伴随着rtx显卡的性能提升,尤其是拥有24gb庞大显存的rtx 4090显卡的出现以及nvidia studio驱动的到来,越来越多的工作室开始购买geforce游戏显卡作为图像渲染卡,而英伟达也不断地往游戏显卡中塞入全新的渲染引擎,让这些专业工作者能够拥有更加高效的图形与画面渲染。
这一次加入的引擎分别是opacity micromask引擎以及micro-mesh引擎,前者用于光追渲染,借助这个引擎,光追中的alpha-test几何性能最高提升2倍。而后者则是在不损耗存储资源,并且采用简易bvh的前提下,提升渲染画面的丰富度,相比较过去,图像的建模速度也有着巨大的提升,而这样功能也获得了adobe等专业应用厂商的认可。
此外老黄还在rtx 40系显卡中支持了着色器重排序,与cpu的乱序执行一样,渲染任务队列可以根据实际需求进行更换,从而大幅提升图像的渲染效率以及gpu的利用率,换算到游戏中,就是提升25%左右的游戏性能,光追性能提升更是最高达到3倍。
目前伴随着nvidia studio等驱动的应用,游戏卡与专业卡之间的界限越来越模糊,而借助最新的技术,专业用户也能享受新一代gpu带来的出色工作效率,毕竟rtx 4090不仅仅是玩家独享的显卡。
集成八代nvidia编码器:视频与直播用户的最爱
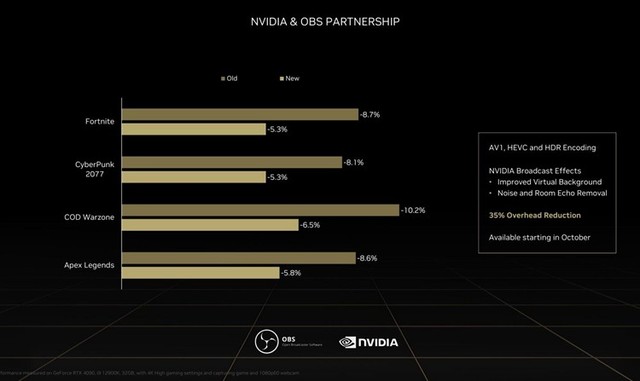
目前直播以及视频制作的兴起也让gpu应该有更多的编解码性能,而英伟达这一次则在rtx 40系显卡中加入了双nvidia编码器,使得视频的输出时间可以减少最多50%,同时也支持av1编解码,而像obs、blackmagic design davinci resolve等设计与直播软件也加入了nvencav1编码器,可以让rtx 40系显卡有着发挥的空间。
nvidia broadcast软件开发工具包增加了面部表情预估,眼神追踪,以及虚拟绿幕质量改进三项功能,让直播up主直播起来更具沉浸感,当然对于会议用户也是大有所益。
卡皇最具性价比
最后还是绕不开本次rtx 40系显卡的核心争议点那就是价格。由于更高的晶圆制造成本以及汇率,英伟达rtx 40系显卡的建议零售价相比较rtx 30系有所提升也是在预料之内,但是出乎意料的是,没想到这一次显卡的价格提升幅度实在是让消费者难以接受,rtx 4080 12gb售价为7199元,而rtx 4080 16gb售价为9499元,相比较rtx 3080 5499元的建议零售价来说实在是过于凶猛。而作为卡皇的rtx 4090反而是三款显卡中最具性价比的一款,原因是12999元的建议零售价比上代提升了1000元,当然提升的性能幅度显然对得起卡皇的售价。
而另外两款就不一定了,rtx 4080 16gb采用9728个cuda核心,搭载16gb gddr6x显存,性能相当于两倍的rtx 3080 ti,而rtx 4080 12gb则采用7680个cuda核心,搭载的是12gb的gddr6x显存,性能也超过了rtx 3090ti。在官方给出的游戏表现中,在光栅游戏下,rtx 4080 12gb与rtx 3090 ti不相上下,部分游戏略输,而rtx 4080 16gb则比rtx 3090 ti提升20%左右。
对于英伟达来说,显然需要rtx 4080系列显卡拥有一个强有力的表现,来让消费者接纳这两款显卡,毕竟经过了2年的矿潮,现在消费者的热情已经来到了底谷,再想恢复并不是一件容易的事情。
编辑:张书嘉
相关热词搜索:
表达看法

